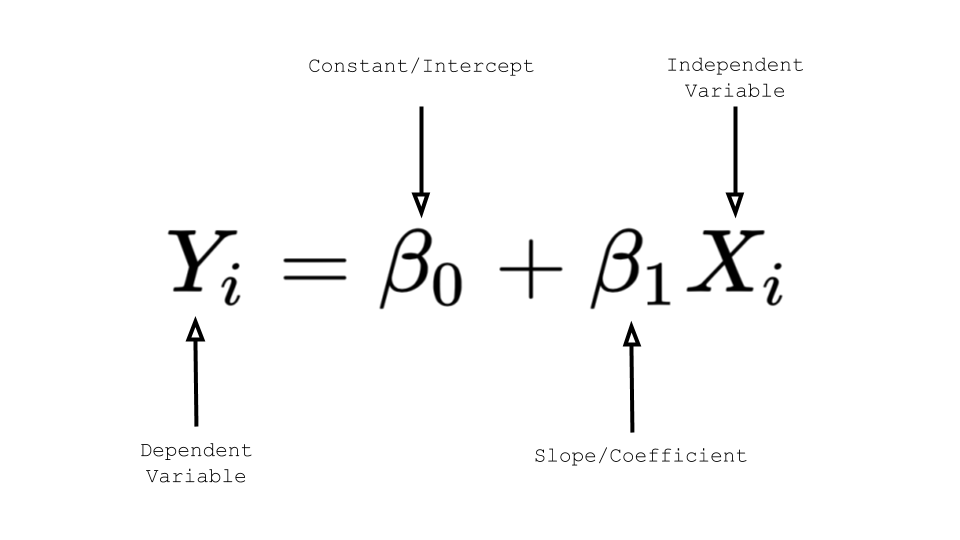In this article, I will define what linear regression is in machine learning, delve into linear regression theory, and go through a real-world example of using linear regression in Python.
What is Linear Regression?
Linear regression is a machine learning algorithm used to measure the relationship between two variables. The algorithm attempts to model the relationship between the two variables by fitting a linear equation to the data.
In machine learning, these two variables are called the feature and the target. The feature, or independent variable, is the variable that the data scientist uses to make predictions. The target, or dependent variable, is the variable that the data scientist is trying to predict.
Before attempting to fit a linear regression to a set of data, you should first assess if the data appears to have a relationship. You can visually estimate the relationship between the feature and the target by plotting them on a scatterplot.
If you plot the data and suspect that there is a relationship between the variables, you can verify the nature of the association using linear regression.
Linear Regression Theory
Linear regression will try to represent the relationship between the feature and target as a straight line.
Do you remember the equation for a straight line that you learned in grade school?
y = mx + b, where m is the slope (the number describing the steepness of the line) and b is the y-intercept (the point at which the line crosses the vertical axis)
Equations describing linear regression models follow this same format.
The slope m tells you how strong the relationship between x and y is. The slope tells us how much y will go up or down for a given increase or decrease in x, or, in this case, how much the target will change for a given change in the feature.
In theory, a slope of 0 would mean there is no relationship at all between the data. The weaker the relationship is, the closer the slope is to 0. But if there is a strong relationship, the slope will be a larger positive or negative number. The stronger the relationship is, the steeper the slope is.
Unlike in pure mathematics, in machine learning, the relationship denoted by the linear equation is an approximation. That’s why we refer to the slope and the intercept as parameters and we must estimate these parameters for our linear regression. We even use a different notation in which the intercept constant is written first and the variables are greek symbols:
Even though the notation is different, it’s the exact same equation of a line y=mx+b. It is important to know this notation though because it may come up in other linear regression material.
But how do we know where to make the linear regression line when the points are not straight in a row? There are a whole bunch of lines that can be drawn through scattered data points. How do we know which one is the “best” line?
There will usually be a gap between the actual value and the line. In other words, there is a difference between the actual data point and the point on the line (fitted value/predicted value). These gaps are called residuals. The residuals can tell us something about how “good” of an estimate our line is making.
Look at the size of the residuals and choose the line with the smallest residuals. Now, we have a clear method for the hazy goal of representing the relationship as a straight line. The objective of the linear regression algorithm is to calculate the line that minimizes these residuals.
For each possible line (slope and intercept pair) for a set of data:
- Calculate the residuals
- Square them to prevent negatives
- Add the sum of the squared residuals
Then, choose the slope and intercept pair that minimizes the sum of the squared residuals, also known as Residual Sum of Squares.
Linear regression models can also be used to estimate the value of the dependent variable for a given independent variable value. Using the classic linear equation, you would simply substitute the value you want to test for x in y = mx + b; y would be the model’s prediction for the target for your given feature value x.
Linear Regression in Python
Now that we’ve discussed the theory around Linear Regression, let’s take a look at an example.
Let’s say we are running an ice cream shop. We have collected some data for daily ice cream sales and the temperature on those days. The data is stored in a file called temp_revenue_data.csv. We want to see how strong the correlation between the temperature and our ice cream sales is.
import pandas
from pandas import DataFrame
data = pandas.read_csv('temp_revenue_data.csv')
X = DataFrame(data, columns=['daily_temperature'])
y = DataFrame(data, columns=['ice_cream_sales'])
First, import Linear Regression from the scikitlearn module (a machine learning module in Python). This will allow us to run linear regression models in just a few lines of code.
from sklearn.linear_model import LinearRegression
Next, create a LinearRegression() object and store it in a variable.
regression = LinearRegression()
Now that we’ve created our object we can tell it to do something:
The fit method runs the actual regression. It takes in two parameters, both of type DataFrame. The feature data is the first parameter and the target data is the second. We are using the X and y DataFrames defined above.
regression.fit(X, y)
The slope and intercept that were calculated by the regression are available in the following properties of the regression object: coef_ and intercept_. The trailing underline is necessary.
# Slope Coefficient
regression.coef_
# Intercept
regression.intercept_
How can we quantify how “good” our model is? We need some kind of measure or statistic. One measure that we can use is called R2, also known as the goodness of fit.
regression.score(X, y)
output: 0.5496...
The above output number (in percentage) is the amount of variation in ice cream sales that is explained by the daily temperature.
Note: The model is very simplistic and should be taken with a grain of salt. It especially does not do well on the extremes.