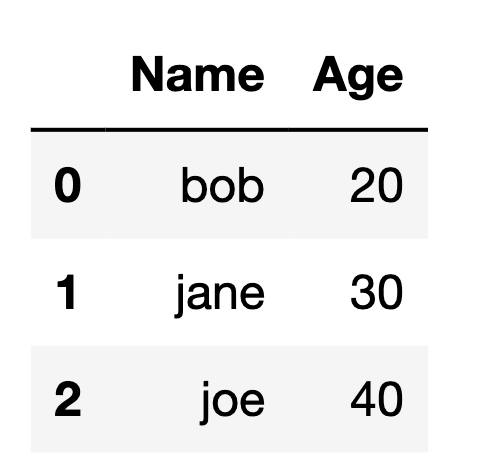
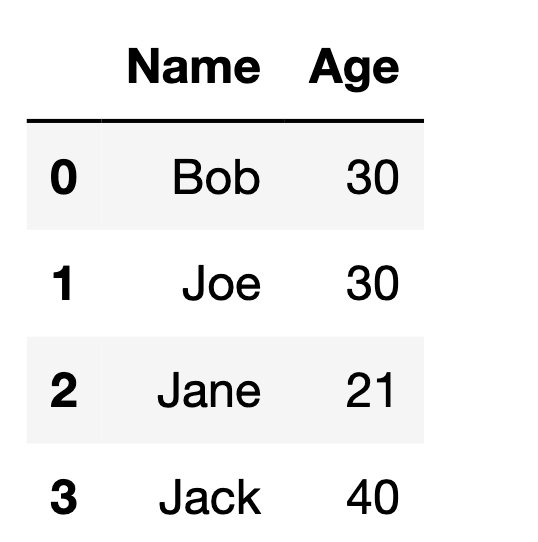
In this article, I’ll be explaining why you should split your dataset into training and testing data and showing you how to split up your data using a function in the scikitlearn library.
If you are training a machine learning model using a limited dataset, you should split the dataset into 2 parts: training and testing data.
The training data will be the data that is used to train your model. Then, use the testing data to see how the algorithm performs on a dataset that it hasn’t seen yet.
If you use the entire dataset to train the model, then by the time you are testing the model, you will have to re-use the same data. This provides a slightly biased outcome because the model is somewhat “used” to the data.
We will be using the train_test_split function from the Python scikitlearn library to accomplish this task. Import the function using this statement:
from sklearn.model_selection import train_test_split
This is the function signature for the train_test_split function:
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
The first parameters to the function are a sequence of arrays. The allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
So the first argument is gonna be our features variable and the second argument is gonna be our targets.
# X = the features array
# y = the targets array
train_test_split(X, y, ...)
The next parameter test_size represents the proportion of the dataset to include in the test split. This parameter should be either a floating point number or None (undefined). If it is a float, it should be between 0.0 and 1.0 because it represents the percentage of the data that is for testing. If it is not specified, the value is set to the complement of the train size.
This is saying that I want the test data set to be 20% of the total:
train_test_split(X, y, test_size=0.2)
train_size is the proportion of the dataset that is for training. Since test_size is already specified, there is no need to specify the train_size parameter because it is automatically set to the complement of the test_size parameter. That means the train_size will be set to 1 – test_size. Since the test_size is 0.2, train_size will be 0.8.
The function has a shuffle property, which is set to True by default. If shuffle is set to True, the function will shuffle the dataset before splitting it up.
What’s the point of shuffling the data before splitting it? If your dataset is formatted in an ordered way, it could affect the randomness of your training and testing datasets which could hurt the accuracy of your model. Thus, it is recommended that you shuffle your dataset before splitting it up.
We could leave the function like this or add another property called random_state.
random_state controls the shuffling applied to the data before applying the split. Pass an int for reproducible output across multiple function calls. We are using the arbitrary number 10. You can really use any number.
train_test_split(X, y, test_size=0.2, random_state=10)
The function will return four arrays to us: a training and testing dataset for the feature(s), and a training and testing dataset for the target.
We can use tuple unpacking to store the four values that the function returns:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
Now, you can verify that the splitting was successful.
The percent of the training set will be the number of rows in X_train divided by the total number of rows in the dataset as a whole:
len(X_train)/len(X)
The percent of the testing dataset will be the number of rows in X_test divided by the total number of rows in the dataset:
len(X_train)/len(X)
The numbers returned by these calculations will probably not be exact numbers. For example, if you are using an 80/20 split, then this division by give you numbers like 0.7934728 instead of 0.80 and 0.1983932 instead of 0.20.
That’s it!