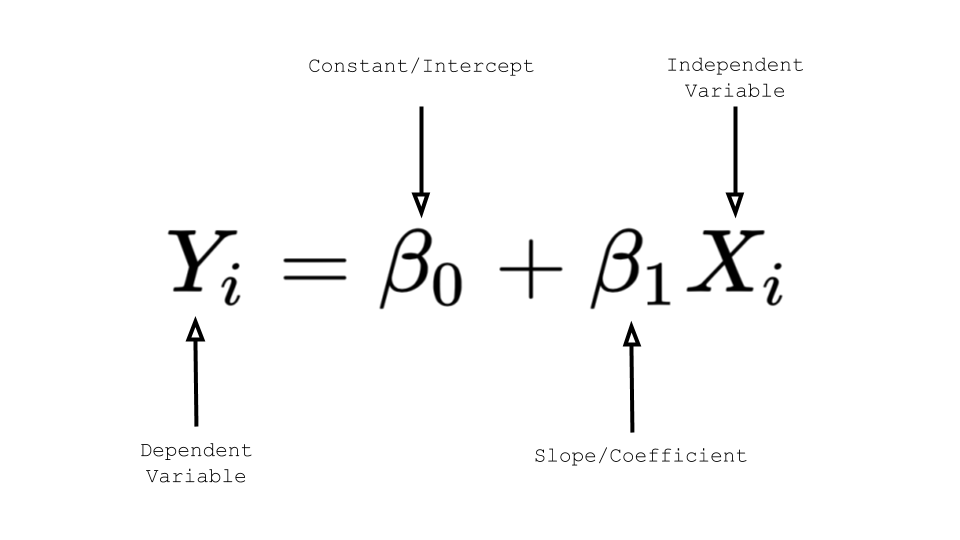You’ve probably heard of machine learning models that can read human handwriting or understand speech. You might know that these models had to be trained in order to accomplish these tasks– they had to learn. But how exactly does a machine “learn”? What are the steps involved?
In this article, I’m going to be giving a high-level overview of how the “learning” in machine learning happens. I’m going to talk about fundamental ML concepts including cost functions, optimization, and linear regression. I’ll outline the basic framework used in most machine learning techniques.
Data is the foundational of any machine learning model. In a nutshell, the data scientist feeds a bunch of data into the ML model and, as it starts to “learn” from the data, the model will eventually develop a solution. What is the solution? The solution is typically a function that describes the relationship in the data. For a given input, the function should be able to provide the expected output.
In the case of linear regression, one of the most basic ML models, the regression model “learns” two parameters: the slope and the intercept. Once the model learns these parameters to the desired extent, the model can be used to compute the output y for a given input X (in the linear regression equation y = b0 + b1*X). If you’re unfamiliar with linear regression, take a look at my article on linear regression to understand this better.
So now that we know what the goal of machine learning is, we can talk about how exactly the learning happens. The machine learning model usually follows three core steps in order to “learn” the relationship in the data as described by the solution function:
- Predict
- Calculate the error
- Learn
The first step is for the model to make a prediction. To start, the model may make arbitrary guesses for the values that it is solving for in the solution function. In the case of linear regression, the ML model would make guesses for the values of the slope and intercept.
Next, the model would check its prediction against the actual test data and see how good/bad the prediction was. In other words, the model calculates the error in its prediction. In order to compare the prediction against the data, we need to find a way to measure how “good” our prediction was.
Finally, the model will “learn” from its error by adjusting its prediction to have a smaller error.
The model will repeat these 3 steps– predict, calculate error, and learn– a bunch of times and slowly come to the best coefficients for the solution. This simple 3-step algorithm is the basis for training most machine learning models.
When I talked about calculating error earlier, I didn’t talk about the ways in which we measure how “good” or “bad” our predictions are. That leads me to the next topic: cost functions. In machine learning, a cost function is a mechanism that returns the error between predicted outcomes and the actual outcomes. Cost functions measure the size of the error to help achieve the overall goal of optimizing for a solution with the lowest cost.
The objective of an ML model is to find the values of the parameters that minimize the cost function. Cost functions will be different depending on the use case but they all have this same goal.
The Residual Sum of Squares is an example of a cost function. In linear regression, the Residual Sum of Squares is used to calculate and measure the error in predicted coefficient values. It does this by finding the sum of the gaps between the predicted values on the linear regression line and the actual data point values (check out this article for more detail). The lowest sum indicates the most accurate solution.
Cost functions fall under the broader category of optimization. Optimization is a term used in a variety of fields, but in machine learning it is defined as the process of progressing towards the defined goal, or solution, of an ML model. This includes minimizing “bad things” or “costs”, as is done in cost functions, but it also includes maximizing “good things” in other types of functions.
In summary, machine learning is typically done with a fundamental 3-step process: make a prediction, calculate the error, and learn / make adjustments. The error in a prediction is calculated using a cost function. Once the error is minimized, the model is done “learning” and is left with a function that should provide the expected result for future data.